Problem
The goal of this project was to build a high-performing classifier for the Kaggle Natural Language Processing with Disaster Tweets task while also making the model’s decisions easier to explain. Classification accuracy alone is not enough in this kind of setting. If the model is going to be trusted, its decisions need to be inspectable.
Context and why it matters
Disaster-tweet classification is a compact but useful NLP problem. The data contains short posts, ambiguous phrasing, hashtags, mentions, and links. That makes it a good case study for two reasons:
- Short texts are difficult to classify reliably because context is limited.
- The same prediction can look plausible for the wrong reason if the model overweights URLs, hashtags, or emotionally loaded words.
The project combined BERT for predictive performance with LIME for local interpretability. The result was a model that performed competitively while still supporting closer inspection of individual predictions.
Data and inputs
The training set contains 7,613 tweets labeled as either real disaster or not real disaster. The inputs are short text snippets with varied writing styles, references to current events, and many noisy artifacts such as links and mentions.
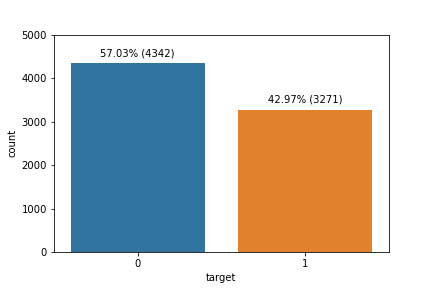
The key challenge in this dataset is not just language understanding. It is separating actual event descriptions from tweets that use dramatic words metaphorically, jokingly, or in unrelated contexts.
Approach
Why BERT plus LIME
BERT was a strong choice because the task depends on word order, context, and token interactions that simpler bag-of-words or n-gram methods often miss. However, better performance creates a second problem: the model becomes harder to explain.
LIME addresses that second problem by showing which words most influenced a specific prediction. It does not make the model simple, but it gives a usable local explanation for a single output.
Model architecture
The model used an uncased large BERT variant from TensorFlow Hub as the base language model, then added a more task-specific classification stack:
- two Bidirectional LSTM layers on top of BERT outputs
- a dense layer with ReLU activation
- dropout for regularization
- a two-unit softmax output layer
This design produced a strong leaderboard result while still supporting predict()
output that integrates cleanly with LIME explanations.
Results
The final model reached a top 4% leaderboard score in the Kaggle competition. That performance made it worth examining more closely. Rather than stopping at the aggregate metric, the next step was to inspect whether the model was making predictions for meaningful reasons.
Two patterns emerged:
- In many correct predictions, the model focused on terms that clearly tracked disaster context, such as evacuation, bomb, or detonated.
- In more ambiguous cases, the explanations suggested that the model was sometimes influenced by peripheral tokens such as URLs, hashtags, or isolated dramatic words.
Example interpretations
The examples below are representative of how the model behaves. The explanations show why local interpretability matters even when the top-line score looks strong.
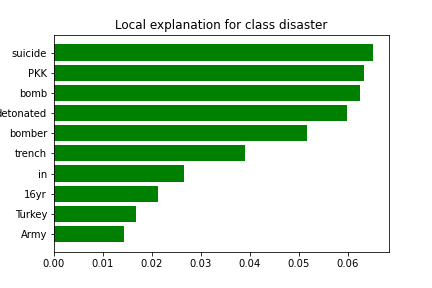
Example interpretation
Pic of 16yr old PKK suicide bomber who detonated bomb in Turkey Army trench released
This is a clean positive example. The prediction aligns with strongly disaster-related terms such as “suicide bomber”, “detonated”, and “bomb”.
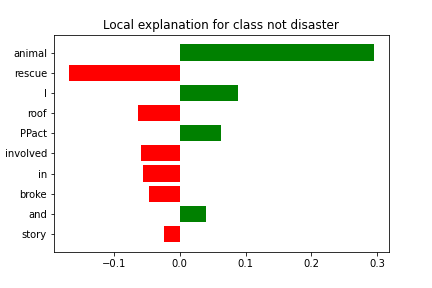
Example interpretation
I'm on 2 blood pressure meds and it's still probably through the roof! Long before the #PPact story broke I was involved in animal rescue
The model handled a noisy tweet correctly, but the explanation still shows uncertainty. Words like “roof” and “rescue” are relevant, but not all strong terms push in the same direction.
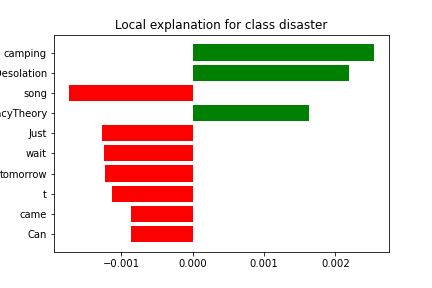
Example interpretation
Just came back from camping and returned with a new song which gets recorded tomorrow. Can't wait! #Desolation #TheConspiracyTheory #NewEP
This is a useful failure-analysis case. The prediction reads as semantically reasonable even though it disagrees with the dataset label, which suggests the example may be mislabeled or at least unusually ambiguous.
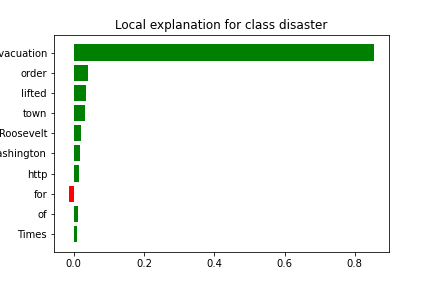
Example interpretation
Evacuation order lifted for town of Roosevelt - Washington Times
The model correctly prioritized event-specific language such as “Evacuation”. This is the kind of signal that gives the system practical value.
Interpretation and limitations
This project shows that strong predictive performance and interpretability can coexist, but only up to a point.
The model works well when the dataset examples align with clear real-world disaster language. It becomes harder to trust when:
- links or formatting artifacts carry too much influence
- metaphorical wording looks similar to literal emergency language
- dataset labels appear noisy
LIME helps reveal those cases, but it does not fully solve them. It explains local behavior, not the complete internal reasoning of the model.
Lessons learned
- Interpretability changes how you evaluate success. A high score can still hide brittle behavior.
- Short texts need context-sensitive models. BERT handled ambiguity much better than simpler methods would have.
- Explanation tools are most valuable on edge cases. The most useful insights came from examples where the model was uncertain, wrong, or plausibly more correct than the label.
- Dataset quality matters as much as model quality. A few questionable labels can distort both evaluation and interpretation.
Next steps
The most obvious next improvements would be:
- strip or normalize URLs before training and explanation
- compare the current stack to a simpler fine-tuned BERT classifier
- review ambiguous or likely mislabeled examples manually
- expand the explanation workflow so users can inspect predictions interactively